 受託開発・お問い合わせ
受託開発・お問い合わせ
視覚言語モデル(VLM)とは?-画像と言語を理解できる生成AIの仕組みと応用-

はじめに
現在、人工知能(AI)の発展は急速に進んでおり、特に視覚情報と言語情報を組み合わせて処理できるVision Language Model(以下、VLM)は、ビジネスに新たな可能性を提供しています。
本記事では、VLMの概要と構造、ビジネス上のインパクトについてご紹介します。
キーワード: 人工知能, AI, Vision Language Model, VLM, Large Language Model, LLM
VLMとは
VLM(Vision Language Model)とは、画像や動画といった視覚情報をテキストで表される言語情報と関連付けることで、従来の画像認識技術では対応しきれなかった複雑なタスクにも取り組むことができる技術です。
画像やテキストのみの単一の情報(モーダルと言います)を扱うCNNなどの技術では、そのデータが示す内容や意味を限定的にしか解釈できません。例えば、CNNを用いた物体検出モデルでは、画像の中に「何があるのか」を識別することはできますが、それが「どのような状況に置かれているか」「他の物体とどのような関係にあるか」といった文脈を理解することは難しいです。

図1: CNNによる物体検出の例(CenterNet): あらかじめ定義・学習した物体が画像のどこにあるかを認識している
一方でVLMは、視覚と言語の情報を相互に補完し合うことで、単純な情報処理を超えた「理解」に近づいています。例えば、製造業においては、機械の異常を示す画像データと、それに関連する説明やエラーコードのテキストデータを結びつけることで、問題を特定し、適切な対応を提示することができます。また、医療の分野では、診断画像と患者の症状や診断データを組み合わせて解析することで、より正確な診断支援が可能となります。

図2: VLMによる画像文脈理解の例(GPT-4o): 物体を認識した上でそれぞれの状況を説明している(一部間違いを含む)
このように、VLMは視覚と言語の情報を組み合わせて解釈することにより、データに対するより包括的な「理解」を実現し、さまざまな業界での応用を可能にしています。
LLMとの違い
VLMは、画像を見れるようになったLLMと捉えることができます。
大量のテキストデータを学習することにより、高度な言語理解や創発性を獲得しているLLMが、画像を見れるようになる。つまり、VLMはLLMと比べて画像から得られる視覚情報をテキストから得られる言語情報と結びつける能力を獲得している点で違いがあります。
この能力により、上記の図2に示されているように、画像とテキストに対して、適切な応答を出力することが可能になっています。
では、どのようにしてVLMはこのような能力を獲得できるのでしょうか?
次の項目では、VLMの構造の観点から、視覚と言語の情報を結びつけるモデルについてイメージを解説します。
VLMの構造
VLMは、その入力内容と出力内容によって、大きく以下の三つに分類されています。
– 視覚とテキストの関係性理解に特化したモデル
– 画像と言語など複数のモダリティ(マルチモダリティ) の入力を処理してテキスト(単一モダリティ)出力を生成するモデル
– 複数のモダリティを入力し複数のモダリティを出力するモデル
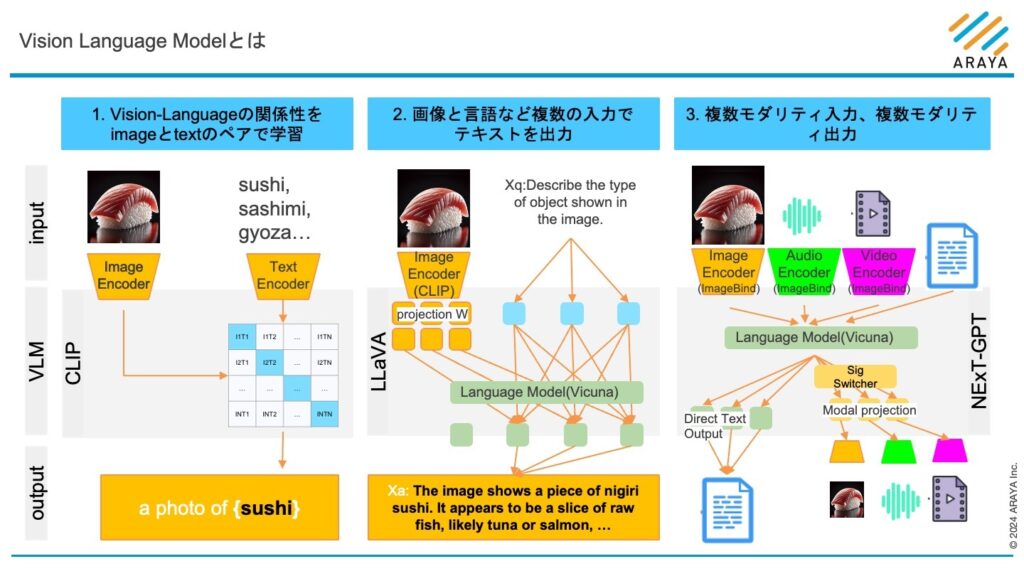
図3: https://arxiv.org/pdf/2404.07214 の分類を元に、 Vision Language Modelの構造と種類を分類し、 VLMの構造は各論文を参考に作成
以降の項目で、各モデルの構造について説明します。
各Vision Language Modelの構造の詳細
視覚とテキストの関係性理解に特化したモデル
図3の「1. Vision-Languageの関係性をimageとtextのペアで学習」では、画像に何が写っているか単語のリストから選択するモデルを例示しています。
このモデルは、視覚とテキストの関係性を画像とテキストのペアから学習し、画像を単語と紐付けて「理解」する潜在空間を構築することで画像とテキストの類似性を判断する能力を獲得しています。
この例では、寿司の画像と同時に候補となる単語リスト(”sushi”, ”sashimi”, “gyoza”…)を候補として入力し、画像と単語の類似度を比較し、最も高かった”Sushi”という回答を得ています(実際の単語リストは、openai/CLIPで公開されているdata/prompts.mdからFood101を利用)。
VLMの能力
ここで、VLMが持つ優れた能力についてご紹介します。
VLMは学習時、最も大事な特徴として、事前に特定のクラスで学習されていなくても回答の候補となる単語リストを更新するだけで画像を分類することが可能な能力(ゼロショット学習といいます) を獲得しています。
これまでの多くの画像認識モデルでは、固定された単語リスト(クラスといいます)で事前に学習し、固定のクラスのみを分類することが多く、単語のリスト、つまりクラスやクラス数が更新された時に、再学習が必要でした。VLMは、ゼロショット学習能力により再学習なしでクラスの更新を行うことが可能です。この能力を持つCLIPと呼ばれるモデルが開発されたことがVLM技術の進歩に大きく貢献しています。
複数のモダリティの入力を処理してテキスト出力を生成するモデル
図3の「2. 画像と言語の複数の入力でテキストを出力」では、画像と指示テキストを入力して、指示に応じた回答をテキスト出力するモデルを例示しています。
このモデルは、言語とペアで学習された柔軟な物体検出能力で画像から言語と関連する特徴を抽出し、指示文と一緒に大規模言語モデルに入力することで、画像に含まれる言語的な特徴と、指示文を合わせて豊かな文脈の理解と自然な回答の生成ができます。
このようなモデルは、「1.視覚とテキストの関係性理解に特化したモデル」の一つの発展型と考えることができ、近年のVLMが出力を単語や短いフレーズに限定せずより自然に対話的な説明を行えるようになっていることを示しています。
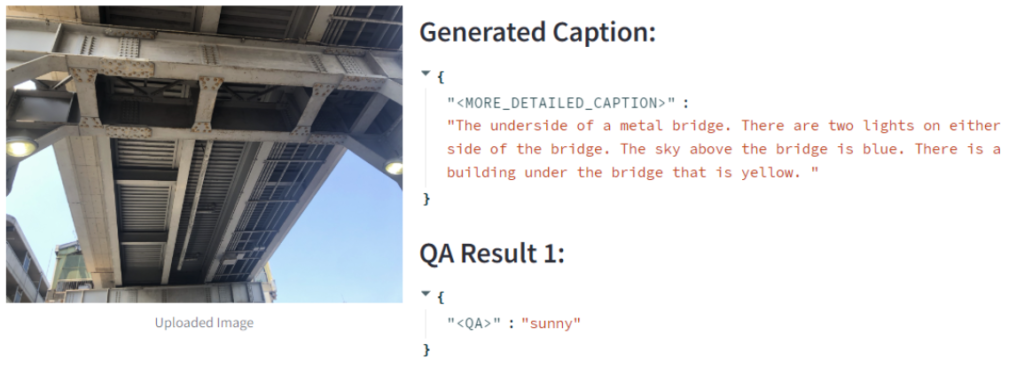
例えば、風景の画像を入力すると、その中に含まれる要素(山、川、建物など)を言語的に説明したり、それらに関する質問に答えたりすることができます。これは、ある陸橋の下からの写真ですが、詳細なキャプションとして、下から見た鉄の橋であること、二つの電球があることなどを説明してくれています。また、QA Result では、この画像の天気はという質問に対して、晴と回答することができています。このような形で画像内の情報の構造化などに活用が進んでいます。
複数のモダリティ入出力を行うモデル
ここまでは、主に視覚情報とテキスト情報について説明してきましたが、最近では、「複数モダリティ入力、複数モダリティ出力」することができる、より高度なマルチモーダルAIモデルも登場してきています。
図3の「3. 複数モダリティ入力、複数モダリティ出力」では、画像や音声、ビデオと言語を入出力することができるモデルを例示しています。
このモデルでは、CLIPを発展させた言語とペアで学習された柔軟な物体検出能力を持つエンコーダ(例えばImageBind)を使用して、画像や音声、ビデオから言語と関連する特徴を抽出します。そして、これらの特徴を質問文や指示文と一緒に大規模言語モデル(Vicunaなど)に入力することで、入力されたマルチモーダルな情報を統合的に理解し、豊かな文脈の中で自然な回答や対応するモダリティの出力を生成することが可能となっています。画像やテキストに限らず、音声や動画などの情報を扱うことで、より豊かな文脈を「理解」することや、画像や音声、ビデオといったより多様なモダリティでの出力も可能にしています。
例えば、風景の画像を入力すると、その中に含まれる要素(山、川、建物など)を言語的に説明したり、それらに関する質問に答えるだけでなく、「この風景に合った音楽を作ってください」というリクエストに対して、適切な音楽を生成することもできます。また、「この風景をもとに短いビデオを作成してください」という依頼に対して、関連するビデオクリップを生成することも可能です。
現在は、複数のモダリティを組み換え可能な形で用意し、任意の入力の組み合わせと出力の組み合わせにできるようにする試みなども行われており、言語を中心とすることでより柔軟な理解と生成ができるようになっていくことが期待されています。
VLMのビジネス上のインパクト
AI開発・運用サイクルの変化
画像認識AIの登場によって、物体認識結果をもとにしたセキュリティ機能や製造業における危険管理、飼育個体数管理などがこれまで達成されてきました。
しかしながら、これらの画像認識AIは、事前にデータから検出したい情報を人手で十分に時間をかけて丁寧に準備された状態で学習されたAIによるもので、検出対象の変更などユースケースごとにモデルを作ることが求められていることが多くありました。特に、画像認識AIで検出した後の処理プロセス自体を専用で設計することが求められることが多く、画像認識から物体・領域を検出するAIとしては機能するが、ユースケースを大幅に変えるには再開発が必要でした。
VLMの登場は、AIの学習サイクルそのものを変更し、これらのAI開発・運用のサイクルに根底から変えていくような進化をもたらす可能性があります。
あらゆるモノ・課題へのAI活用の加速
学習を行わずにあらゆる場面でロボットやAIと現実世界の共通認識をもとにコミュニケーションを取ること、自然言語によって現実世界を操作することへの関心が急速に高まってきています。
GoogleやMetaなどのビックテックをはじめ多くの企業がVLMを活用した自然なコミュニケーション可能な状態での自動化や、画像やスライドなどデータへのアクセシビリティの改善、VLMの生成機能と認識機能を活用した物理世界のシミュレーションを行うモデルへの開発などが取り組まれています。
このように、多様なモーダルを理解できるVLMによって、あらゆるモノへのAIを搭載、あらゆる課題へのAIの活用が加速し始めています。
まとめ ~VLM導入実現に向けて~
本記事では、ビジネスに新たな可能性を提供するVLMというAI技術について、その特徴や構造、ビジネス上のインパクトについて紹介しました。
VLMの活用事例や、VLM発展の歴史、導入における課題など、より具体的な内容についてはこちらのホワイトペーパーで詳細に紹介しています。ぜひご参照ください。

VLMの登場は、これまで実社会の中で、人向けに画像や音声で作成されていたフィードバックやシグナルをVLMやマルチモーダルLMが活用できるようになってきてることを示しており、実社会の中に、あなたの隣に、AIが或る社会が駆け足で近づいてきていることを示しています。
詳細はこちらの資料から。
この資料でわかること
- 画像生成AI(拡散モデル)を用いたアート作品生成
- 大規模言語モデル(LLM)を用いた回答生成の処理
- アラヤの強み
- 会社紹介
アラヤでは、VLMのような先進的な技術活用を検討するためのPoCから、システムインフラの構築、エッジAI化を通したプロダクト化支援まで、幅広く皆様の到達したい未来に一緒に伴走することが可能です。ぜひお気軽にご相談ください。
先端AI開発支援 : https://www.araya.org/service/aisupport/
エッジAIソリューション:https://www.araya.org/service/edgeaiconsulting/

