 受託開発・お問い合わせ
受託開発・お問い合わせ
最新エッジAI技術のトレンド






活用事例5:蒸留を用いた軽量モデルの学習
お客様の工場の異常検知AIモデルに対し、深層学習モデルの汎化性能の向上と知識転移の技術として、手法の一つである蒸留によるモデル圧縮を検討しました。エッジ化の実現に向けて精度が良い小型な軽量モデルが必要な場合などに効果的なアプローチであると考えて研究開発を進め、エッジAI実装にみられる以下の問題を解決することを目的に蒸留※によるモデル小型化行いました。
【エッジAI実装の問題】
モデル圧縮などのエッジAI関連技術は、圧縮により必ずしも高速化されない、または圧縮により精度が大幅に下がる場合があり、適切な方法を見極めることが必要になります。エッジ化を推進するためにより軽量で精度の優れたモデルの開発を目指しました。
※蒸留とは、一度学習したモデルの知識(予測結果)を別の小さいモデルに継承する手法。これにより、大きいモデルに匹敵する精度を持つ小さいモデルを作ることが期待できる。教師モデル(大きいモデル)の持つ知識を生徒モデル(小さいモデル、軽量であっても良い)に転移させ、転移先モデルの精度上昇、学習高速化を行うことを指す。
異常検知のモデルに、製品部品の画像を正常ラベルと異常ラベルに分類するモデルがあります。
そのモデルに対して、蒸留を用いて生徒モデルの精度を教師モデルの精度に近づけることと、プログラムを作成して蒸留をする、という一連の流れを先方がノウハウとして得ることを目的に軽量モデルにタスクを学習をさせ、以下の実現を目指しました。
・実装可能なモデル数を増やし、使用デバイス数を低減
・異常検知を行うための処理速度向上
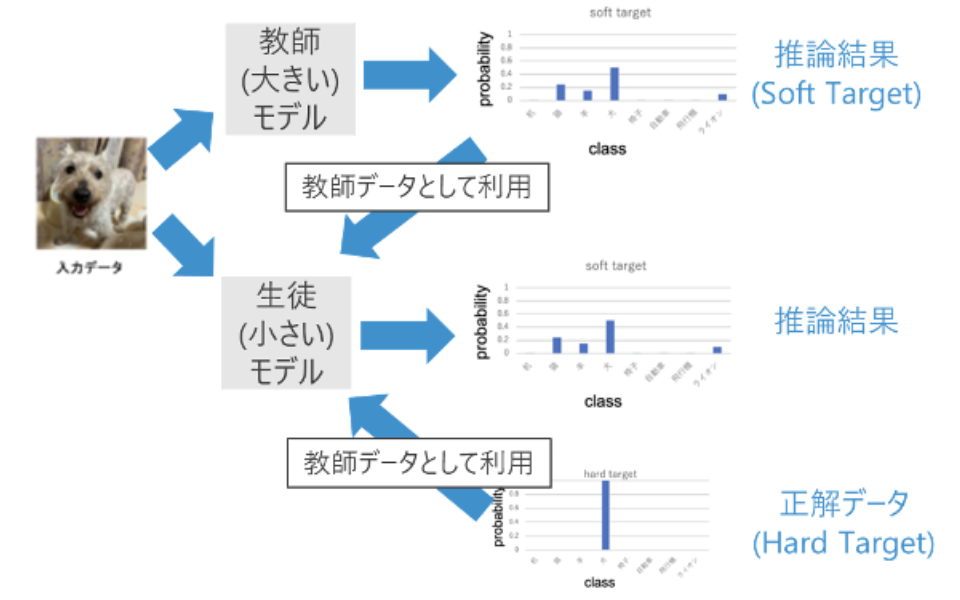
教師モデルの推論結果だけでなく、モデル中間層の出力分布も学習に使用することで、教師モデルに近い性能の小型な生徒モデルを実現しました。
蒸留なしでの学習に対し、蒸留を用いた軽量モデルへの学習の方が誤検出率を約40%低下させることができました。
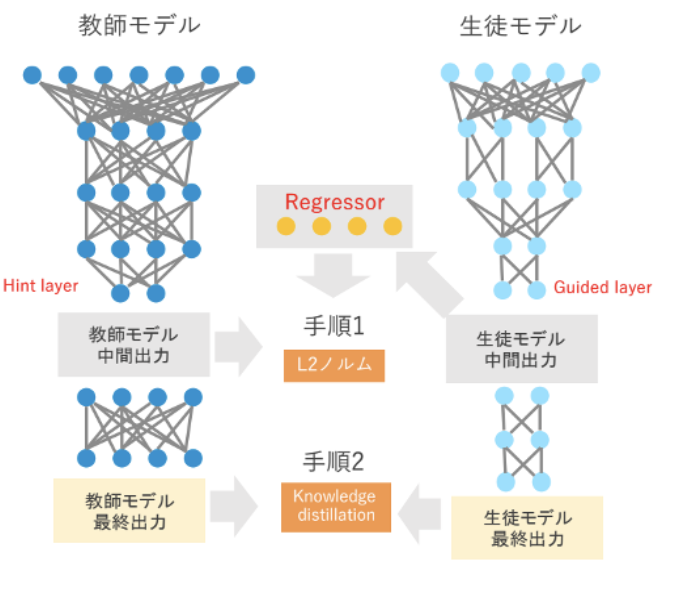
近年のエッジ化の普及に伴い、小型モデルで精度を出したいという需要はますます高まっています。
蒸留という技術はその需要にフィットしており、蒸留技術の知見や実装経験がないというお客様の開発をご支援いたします。
活用事例6:量子化/TensorRT化によるモデルの高速化
お客様の小売向けアプリケーションで利用されている商品検出モデルは大量の画像処理を行うために処理時間が問題となっていました。
この処理時間を高速化をするために量子化を行いました。
結果として精度劣化をすることなく処理速度の向上を実現することができ、モデルエッジ化で高い精度を維持しつつ高速化をされたい場合に有用です。
エッジAIでは端末側に搭載したAIが高速に処理を行うことができなければ実用化ができないケースもあります。
量子化(Int8化)/FP16化とTensorRT化を並行して実施することで、精度はほぼ劣化なく、処理速度の向上を実現しました。
顧客モデルに対して量子化(Int8化)/FP16化とTensorRT化を並行して実施することで、精度はほぼ劣化なく、処理速度の向上を実現しました。
・処理速度
TensorRT化(Darknet→TensorRTに変換して、速度と精度の評価を実施し、最大2倍近くの推論処理速度向上を実現しました。
・精度
精度はほぼ劣化なく、処理速度は向上することができました。
検証としては品切れチェックを実施し、FP16化での精度結果は従来の精度と変わらない結果を実現しました。

モデルの高速化のために以下の最適化を実施しました。
・量子化(Int8化)/FP16化
・TensorRT化
量子化とは、重みなどのパラメタをより小さいビットで表現することで、モデルの軽量化を図る手法です。
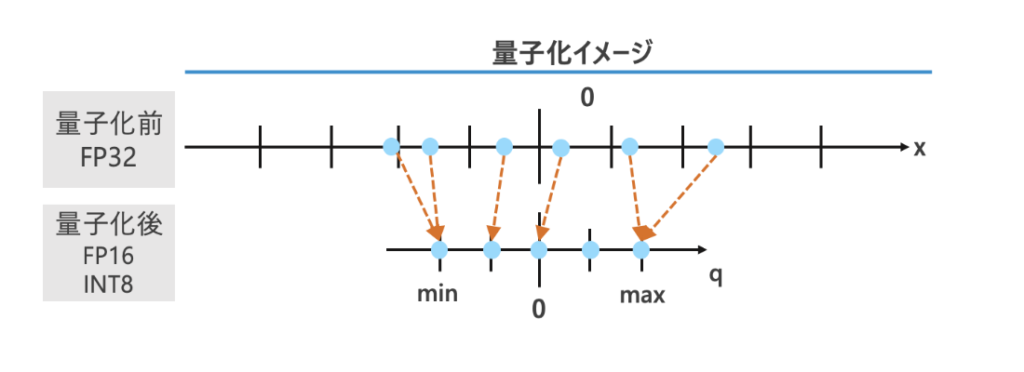
信号の大きさを離散的な値で近似的に表示します。2bitで量子化する場合、min/maxを設定しその範囲を4分割、量子化前の値を量子化後の近い値に割り当てます。
※量子化とは信号の大きさを離散的な値で近似的に表すことである。例えば2bitで量子化する場合、図のようにmin, maxを設定して範囲を4分割し、量子化前の値を量子化後の近い値に割り当てる。必ずしも、min, maxは0で対称である必要はない。範囲を均等に分割しない場合もある。量子化による精度低下を補う手法に、QAT(量子化時の再学習)がある。
TensorRTでの量子化では、min, maxが0で対称、かつ、min, maxの範囲を均等に分割する必要がある。
※TensorRTとは、NVIDIA製の高性能ディープラーニング推論最適化・実行ライブラリ。TensorRTを用いることでネットワークが最適化され、低レイテンシ・高スループットの推論を実現することが可能。
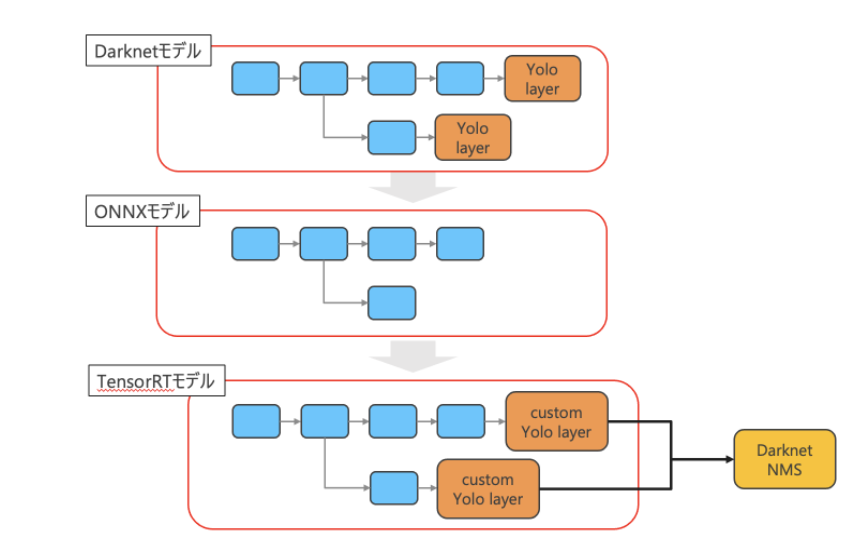
【TensorRTの最適化】
・ネットワーク構造ファイル(.cfg)をパースしてonnxモデルを構成するプログラムを使用
Yolo layer※1はonnxにないためYolo layerを除いてonnxモデルに変換
・TensorRTライブラリを用いてonnxモデルから変換、
cudaで実装されたYolo layerをcustom layerとして追加
推論時のNMS処理は、Darknetで実装されているNMSを使用
エッジAI実装では、端末側で高い精度だけでなく、実用化するためには短時間で処理をする必要があります。この処理時間を高速化をするために量子化を行いました。業務効率化でエッジAIを用いた解決方法を検討される際に、高い精度を維持しつつ高速処理をされたいという幅広い業界のお客様の問題解決に活用することが可能です。

