 受託開発・お問い合わせ
受託開発・お問い合わせ
脳波を用いた深層学習におけるスケーリング則を発見〜非侵襲Speech BMIの実用化に向けた活路へ〜
株式会社アラヤ研究開発部 X Communicationチーム(リーダー:笹井俊太朗)は2024年7月11日(木)に論文「Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data」をarXivに投稿いたしました。以下は本論文についての解説記事になります。
脳-マシンインターフェース(BMI [Brain-Machine Interface])は、身体やコミュニケーションに困難のある方々の支援技術として開発が進んでいます。最近、頭蓋内に埋め込んだ電極で記録した脳信号から、発話の内容を実用可能な精度で解読できることが報告され、注目を集めています。しかし、脳に電極を埋め込む手術は、身体、心理的に負荷が高く、広く社会に普及するための大きなハードルとなっています。これに対し脳波計を用いたBMIは、非侵襲(生体を傷つけない)で、装着や持ち運びも容易であるため、その実用化が望まれています。その一方で、数種類の限られた選択肢から正解を選ぶといった単純なタスクはできても、音声の解読といった自由度の高いタスクでは実用に足る精度が出ないことが報告されており、脳波を用いた発話BMIの実現可能性は疑問視されてきました。
脳波の解読には、深層学習モデルと呼ばれるAI技術が利用されます。ChatGPTなど大規模言語モデル(LLM)での活用で有名な技術ですが、その精度は、訓練データの量、モデルのサイズ、計算リソースの3つの因子でスケールアップするとされています。これは深層学習のスケーリング則と呼ばれており、実際に様々な分野のAI開発や改善の参考にされてきました。その一方で、一般的に脳波の解読は約10時間程度の小規模のデータが用いられており、スケーリング則が存在するかどうかや、それを前提とした解読精度の改善ができるかはわかっていませんでした。
この背景には、そもそもスケーリング則の検証を可能にするような大規模の脳波データをつくることが難しい、という問題がありました。例えば、発話の解読には、文章読み上げといった単調な課題を行っている際の脳波データを蓄積し続けることが必要になります。しかし、単調な課題を毎日長時間、長期にわたって行うことはほとんどの被験者にとって耐え難く、完遂が困難でした。これに対し我々 X Communication チームは、長時間のゲームをプレイすることが苦にならない、ゲーム好きの方に「BMIパイロット」として長期間のデータ取得を行う実験メンバーになってもらいました。実際にゲームを進めつつ、その中で出てくる登場人物の発言を読み上げるという実況プレイのような課題にすることで、協力者が無理なく(むしろ進んで)データを蓄積できる環境をデザインしました(図1)。その結果、合計で400時間を超える文章読み上げ中の脳波データを、同一の被験者から取得することに成功しました。

図1 BMIパイロットによる実験のイメージ図
そこでこの大規模データを用い、自己教師あり表現学習を行う深層学習モデルを用いて、ゼロショット音声フレーズ分類を行いました。取得したデータの中から100時間分のデータを用いてモデルを訓練したところ、512個のフレーズ候補から正解を当てる課題において48%の精度で正答できることが明らかになりました。一方脳波の学習で一般的に利用されるデータ量(約10時間)に限定すると、48%から2.5%にまで精度が低下するといった、著しいスケーリング効果が存在することが明らかになりました(図2)。
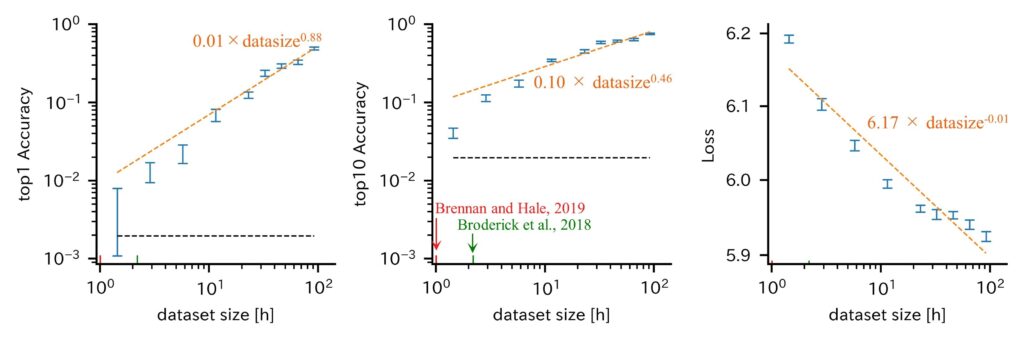
図2 データ量によるスケーリング
モデルの訓練に使用したデータサイズ(時間)と、テストデータを用いたフレーズ分類課題におけるtop 1精度(左)、top 10精度(中央)、およびloss(右)との間にある冪乗則を示しています。黒い破線は分類精度のchance levelを示し、オレンジの破線はデータに対する最良の線形フィットを示します。緑と赤の矢印は、従来の脳波による言語解読の研究で使用されたデータのサイズを示しています。
Broderick, M. P., A. J. Anderson, G. M. Di Liberto, et al. Electrophysiological correlates of semantic dissimilarity reflect the comprehension of natural, narrative speech. Curr. Biol., 28(5):803–809.e3, 2018.Brennan, J. R., J. T. Hale. Hierarchical structure guides rapid linguistic predictions during naturalistic listening. PLoS One, 14(1):e0207741, 2019.
さらに、フレーズの内容だけでなく、単語間の音声の切れ目についても、訓練データの量を増加させるほどより明確に解読できるようになることがわかりました(図3)。これは、フレーズ内の単語についての明示的なラベルを与えなくとも、データ駆動型で音声のセグメントを認識できることを示しています。
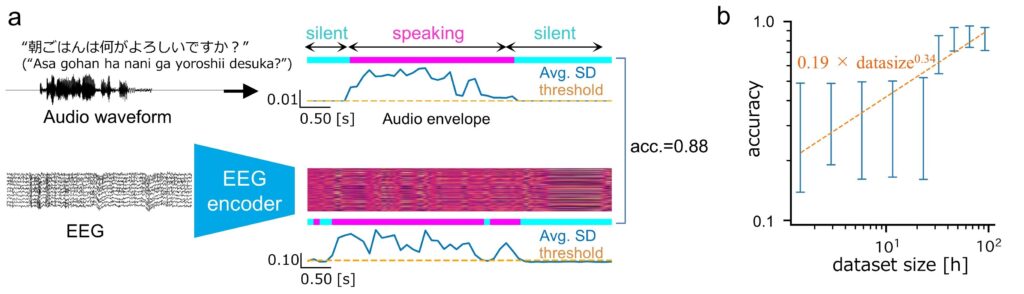
図3 EEGの潜在表現を用いた音声区間の検出
(a) エンコーダによって得られたEEGの潜在表現(カラーマップ)は、解読された音声の状態を表しています。この潜在表現が時間的に大きく変動する区間では音がダイナミックに変化している区間であり、変動の小さい区間は音声出力に対して一定の状態となっていることを示しています。そこで実際に被験者が発した音声と比較したところ、変動の小さい区間では被験者が声を出していないことがわかりました。すなわち、この区間における潜在表現は音を出していないことを示していることがわかりました。そこでEEGの潜在表現から予測された発声のあった区間と、実際の発声データから同定された区間を予測したところ、0.88という一致率であることがわかりました。(b) この一致率は訓練データの量に依存して向上することも確認されました。
文章を読み上げる際には、それに伴って動く表情筋由来の筋電信号が雑音として脳波信号に混入します。そのため、脳波信号をそのままAIモデルの訓練に利用してしまうと、脳波ではなく筋電信号によってフレーズを解読するモデルを構築してしまう恐れがあります。これに対して我々は、あるフレーズAを発話している際の脳波信号に対して、あえて異なるフレーズBを発話している際の筋電信号を足した人工データを創り、そのような人工データを入力された際には、正しいフレーズAを回答するようにモデルを訓練しました(図4)。この方法で訓練したAIモデルに表情筋由来の筋電信号だけを入力した場合は、正答率が大幅に下がることを確認しました(図4)。
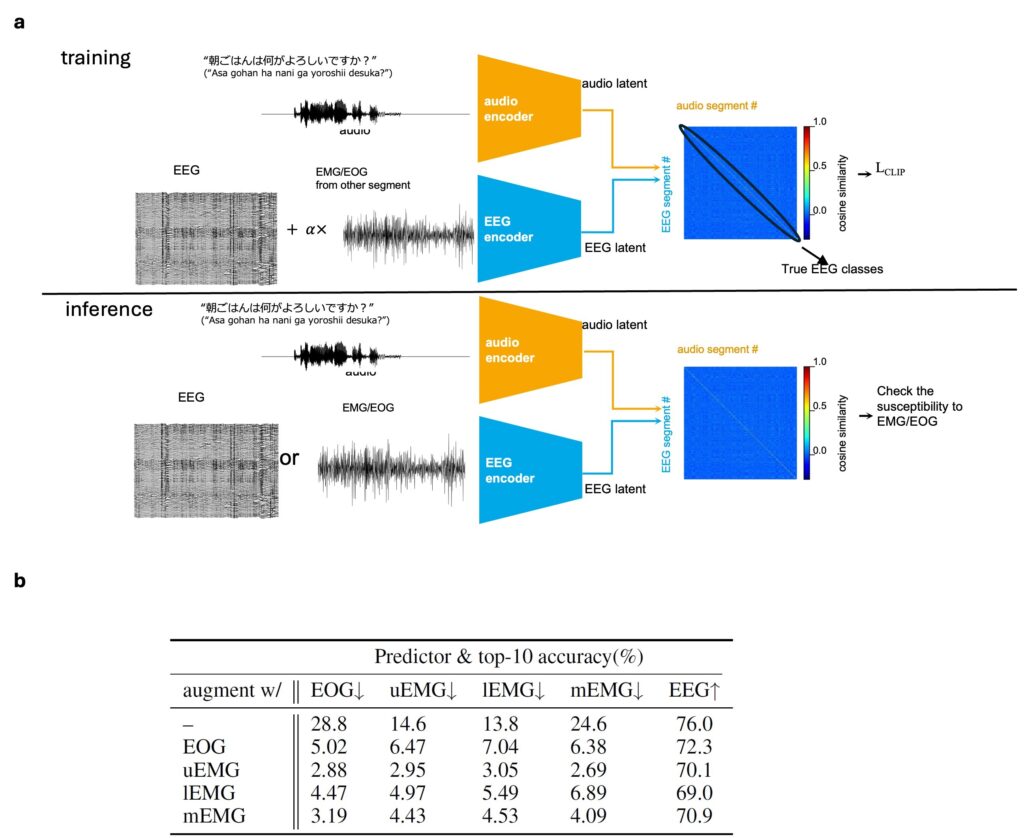
図4 筋電信号の解読への影響を低減するAI学習パラダイム
(a) 筋電の影響を低減して解読を行うAIモデルを訓練するため、筋電と脳波の合成データによるdata augmentationを行いました。ターゲットのフレーズを発話した際の脳波に、異なるフレーズの発話の際に得た筋電を多様な割合で付加したデータをつくり、それを入力した際にはターゲットのフレーズを正答とするよう学習 (ターゲットフレーズのaudio latentと合成EEGのlatentの間でCLIP lossを最小化) を行いました。(b) 筋電を抑制する学習を行わないモデルに対し、筋電信号だけを入力にして解読を行わせた際には、最大で28.8%の精度で正解ができました (top-10 accuracy)。これは脳波 (EEG)を入力した場合の精度(76.0%)と比較して低くはありますが、偶然当たる確率(1.95%)よりも高いことがわかりました。一方(a)の方法で、上唇付近から計測された筋電信号 (uEMG) を使って筋電の影響を抑制したモデルに対し、筋電信号を入力した場合は、筋電位の取得部位に拠らず、最大でも3.05%の精度しか出ないことがわかりました。一方脳波を入力した場合は70.1%の精度でフレーズを解読できることがわかりました。
本研究の結果は、大規模データを用いてAIを訓練することで、脳波から言葉を解読できる可能性を示しており、非侵襲 speech BMIの実現に向けた重要な一歩を示しています。一方、発話中に発生する多様なノイズによる問題を全てクリアできているわけではなく、影響の明確化やよりよい低減手法の開発に向けて研究を推進していきます。
この成果は剃髪が必要な脳波計の利用によるものですが、その必要のない脳波計でのデータ蓄積もすでに始めており、数万時間の脳波を有する大規模データセットを構築する予定です。これに伴って、データ蓄積に協力していただくメンバーも募集しております。特に、神経疾患など様々な理由で身体やコミュニケーションに対して社会にバリアを感じる方々への選択肢となる技術への応用を目指すべく、今後は、本研究開発に共感いただける当事者の方々にも協力していただきながら推進できる環境構築を始めています。詳細は関連リンクの採用ページよりご確認ください。
また、本研究は社会のさまざまな場面で場面への応用ができるのではないかと予想しています。そのためには、分野・業種問わず多岐に渡るステークホルダーの皆様との連携が必要だと感じています。ご興味のある方、取材などをご希望の方はコンタクトフォームよりいつでもご連絡ください。
※本研究は国立研究開発法人 科学技術振興機構(JST)が研究推進を担うムーンショット型研究開発制度 ムーンショット目標1「2050年までに、人が身体、脳、空間、時間の制約から解放された社会を実現」の助成を受けて行われています。
【関連リンク】
X Communication Team:https://research.araya.org/ja/research/x-communication-team
ムーンショット目標1金井プロジェクト Internet of Brains:https://brains.link/
「Neu World」(X Communicationの研究をテーマにした作品を掲載中):https://neu-world.link/
【急募!X Communicationチームメンバー 採用情報】
BMI Researcher/Engineer:https://herp.careers/v1/arayainc/gnuu5n44hjks
BMI テクニシャン:https://herp.careers/v1/arayainc/CORUrPtcgwaI
BMI実験協力者「BMIパイロット」:https://herp.careers/v1/arayainc/NlXz1yTDk72n
【取材・コラボレーション随時募集中!】
お問い合わせは以下のコンタクトページよりお願いいたします。
コンタクトフォーム:https://www.araya.org/contact/